Mir war langweilig und da hab ich mal einen kurzen Python-Code geschrieben, um Grafiken zu erzeugen, die das Preis-Leistungs-Verhältnis von Produkten im Tasting darstellen:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
### Load data
results = pd.read_csv('tastingresults.csv', sep=';', decimal=',')
print(results)
### Prepare figure
fig = plt.figure()
axes = fig.add_subplot(1,1,1)
axes.set_xlabel('Preis (€/l)', fontsize=20)
axes.set_ylabel('Durchschnittliche Bewertung', fontsize=20)
# Figure style
for axis in ['top','bottom','left','right']:
axes.spines[axis].set_linewidth(2)
axes.minorticks_on()
axes.tick_params(which='major', width=2, pad=10, length=10, labelsize=20)
axes.tick_params(which='minor', width=2, pad=10, length=5)
# Figure dimensions
axes.set_xlim(left=0, right=80)
axes.set_ylim(bottom=0, top=10)
axes.xaxis.set_minor_locator(ticker.MultipleLocator(10))
axes.xaxis.set_major_locator(ticker.MultipleLocator(20))
axes.yaxis.set_minor_locator(ticker.MultipleLocator(1))
axes.yaxis.set_major_locator(ticker.MultipleLocator(2))
### Draw figure
axes.plot(results['Preis'],
results['Bewertung'],
'o',
color='orange',
markersize=12,
markeredgewidth=1.5)
if 'Standardabweichung' in results:
axes.errorbar(results['Preis'],
results['Bewertung'],
yerr=results['Standardabweichung'],
fmt='none',
ecolor='orange',
elinewidth=2,
capsize=0,
capthick=2)
for name, price, rating in zip(results['Produkt'],
results['Preis'],
results['Bewertung']):
axes.text(price,
rating + 0.025*(axes.get_ylim()[1] - axes.get_ylim()[0]),
name,
horizontalalignment='center',
#verticalalignment='center',
color='black',
fontsize=13)
### Save figure
fig.tight_layout()
fig.savefig('preisleistung.png')
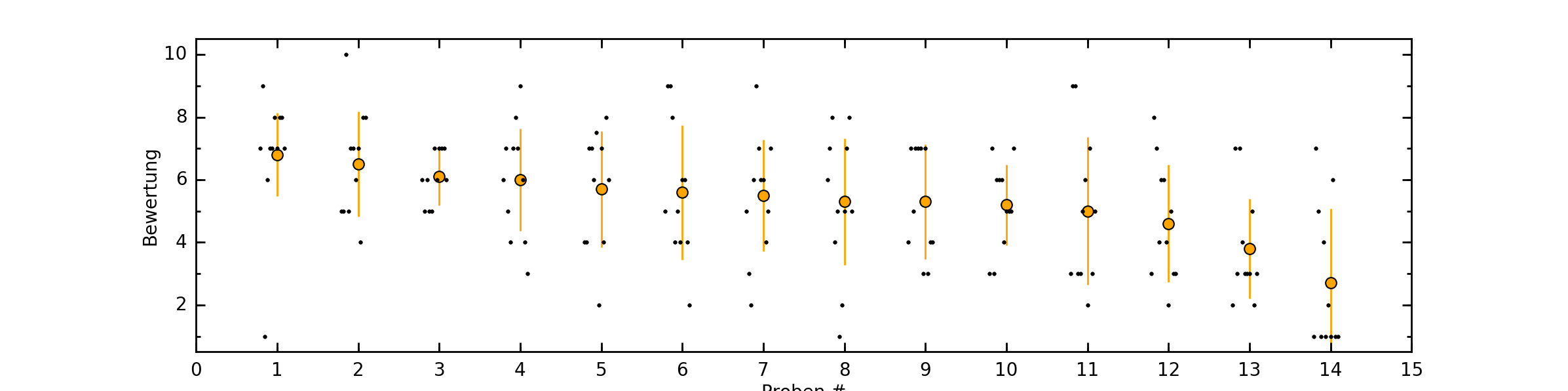
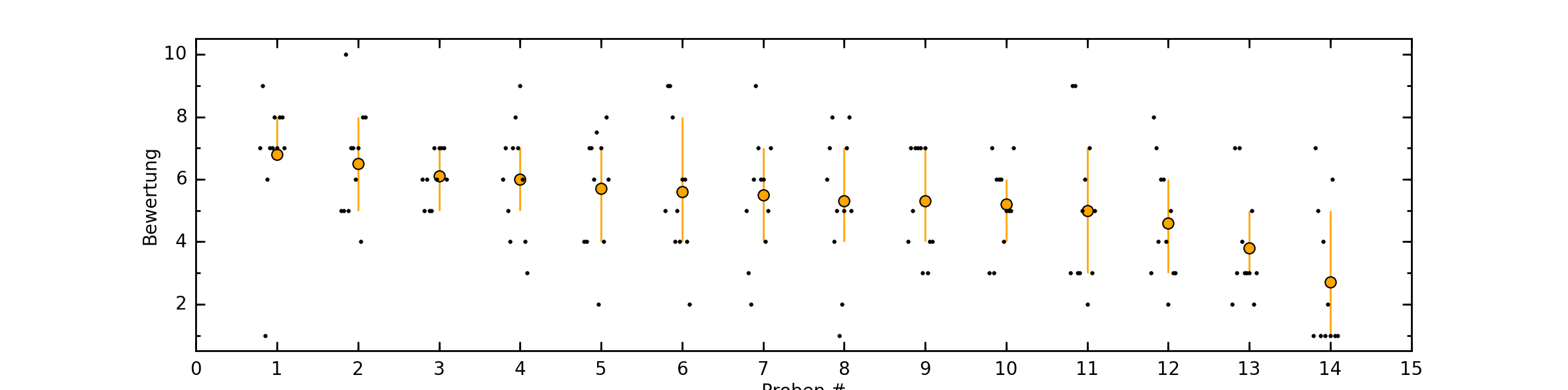
Das Resultat (für @Mixael’s Rye-Tasting) sieht dann etwa so aus:
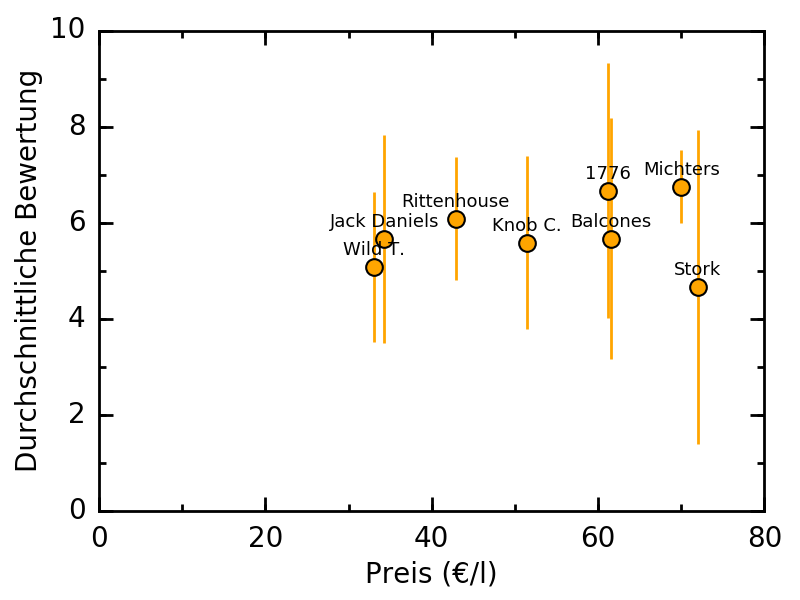
Die Fehlerbalken stellen die Standardabweichung dar und sind ein Maß für die Streuung der Bewertungen.
Man könnte alternativ anstelle der Namen der Produkte auch nur die Nummer aus dem Tasting an den Datenpunkt schreiben. Das ist dann etwas übersichtlicher aber man muss mit einer Tabelle vergleichen.
Bei Produkten mit gleichem Preis habe ich mir erlaubt, diese um 0,10 € zu verschieben, um die Fehlerbalken unterscheiden zu können.
Um das Skript verwenden zu können, muss man die Daten als .csv-Datei Speichern in der folgenden Form:
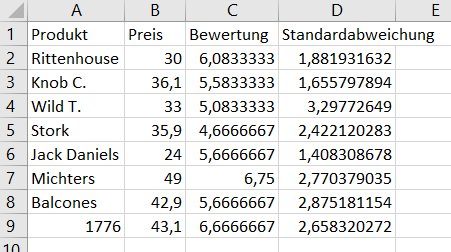
Am Anfang vom Skript sollte man dann noch definieren, ob in der .csv-Datei ein Komma oder Semikolon als Trennzeichen verwendet wird, und ob man die Zahlen mit Komma oder Punkt schreibt.
Die Daten für die Standardabweichung sind optional.
Was haltet ihr von der Darstellung? Falls Interesse Besteht könnte ich das Skript auch dahin gehend erweitern, dass man die Daten von allen Testern einließt und Mittelwert und Standardabweichung automatisch berechnet werden.
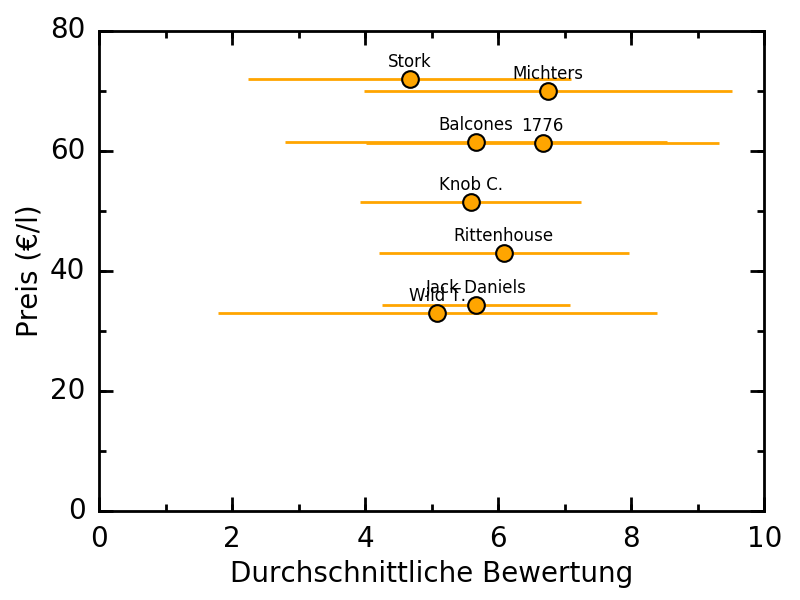


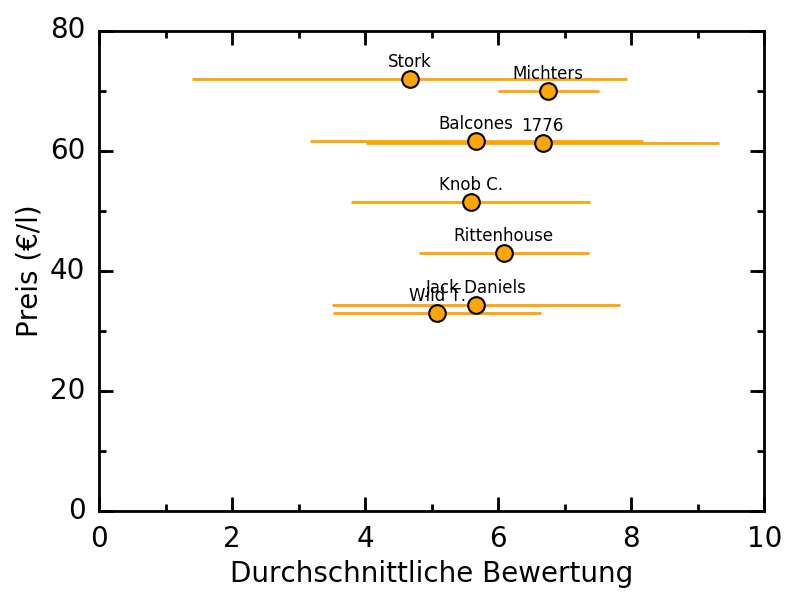
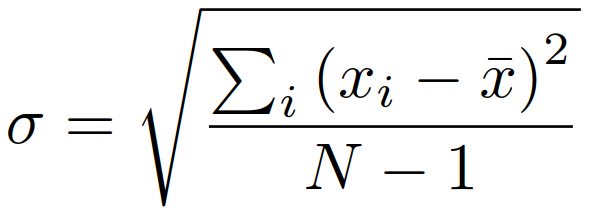




 Die Datei liegt einfach im selben Verzeichnis. Das ganze soll möglichst einfacher verständlicher Code sein. Wenn ich anfangen würde das professioneller zu gestalten würde ich auch sicherlich die Style-Vorlagen für die Figures in einem separaten File global definieren.
Die Datei liegt einfach im selben Verzeichnis. Das ganze soll möglichst einfacher verständlicher Code sein. Wenn ich anfangen würde das professioneller zu gestalten würde ich auch sicherlich die Style-Vorlagen für die Figures in einem separaten File global definieren.